

Audiobooks have gained immense popularity in recent years, with platforms like Amazon’s Audible leading the charge. They offer the convenience of consuming books on the go, whether you’re driving, exercising, or simply relaxing. While several apps can convert PDFs to audio, creating your own audiobooks from PDFs can be equally exciting and useful.
In this blog post, we will walk through a Python project that converts text from a PDF file to speech and saves it as an audio file. We’ll use three libraries: PyPDF2 for reading PDFs, pyttsx3 for text-to-speech conversion, and Streamlit for creating a user-friendly web app.
By the end of this tutorial, you will have your own PDF-to-audiobook converter, empowering you to turn any PDF document into an engaging audio experience.
Prerequisites
Before we begin, open terminal and install the required libraries:
pip install PyPDF2 pyttsx3 streamlitStep 1: Import Libraries:
We will import the following libraries :
PyPDF2: To read PDF files and extract text.
pyttsx3: To convert text to speech.
streamlit: To create the web app interface.
import PyPDF2
import pyttsx3
import streamlit as stStep 2: Initialize TTS Engine
init_tts_engine(rate=200, volume=2.0): Initializes the TTS engine with the specified rate, volume, and sets the voice to a female voice.
engine.setProperty('rate', rate): Sets the speed of speech.
engine.setProperty('volume', volume): Sets the volume level.
voices = engine.getProperty('voices'): Gets the list of available voices.
engine.setProperty('voice', voices[1].id): Sets the voice to the second voice in the list (usually a female voice).
def init_tts_engine(rate=190, volume=2.0):
engine = pyttsx3.init() # Initialize the TTS engine
engine.setProperty('rate', rate) # Set the speech rate (words per minute)
engine.setProperty('volume', volume) # Set the volume level (0.0 to 1.0)
# Select the desired voice
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[1].id) # Set the voice to female
return engineStep 3: Extract Text from PDF
extract_text_from_pdf(pdf_file): Reads the PDF file and extracts text from each page.
full_text += page.extract_text(): Appends the extracted text from each page to a single string.
# Function to read PDF and extract text
def extract_text_from_pdf(pdf_file):
reader = PyPDF2.PdfReader(pdf_file) # Create a PDF reader object
full_text = "" # Initialize an empty string to hold the extracted text
for page_num in range(len(reader.pages)): # Loop through all pages in PDF
page = reader.pages[page_num] # Get the page object
full_text += page.extract_text() # Extract text and append to full_text
return full_textStep 4: Convert Text to Speech and Save to File
text_to_speech(engine, text, output_file): Converts the given text to speech and saves it as an audio file.
engine.save_to_file(text, output_file): Saves the converted speech to a specified file.
engine.runAndWait(): Runs the TTS engine to process the text and generate the audio.
# Function to convert text to speech and save to file
def text_to_speech(engine, text, output_file):
engine.save_to_file(text, output_file) # Save the speech to an audio file
engine.runAndWait() # Run the TTS engine to complete the processStep 5: Streamlit App
We will now make our Streamlit app. Below is the explanation:
st.title("PDF to Audio Converter"): Sets the web app title.
st.file_uploader("Choose a PDF file", type="pdf"): Creates a file uploader for PDFs.
extract_text_from_pdf(uploaded_file): Extracts text from the uploaded PDF.
st.write("Extracted Text:"): Displays the extracted text.
st.button("Convert to Audio"): Button to trigger text-to-speech conversion.
init_tts_engine(): Initializes the TTS engine.
text_to_speech(speaker, text, 'output_audio.mp3'): Converts text to speech and saves it as an MP3.
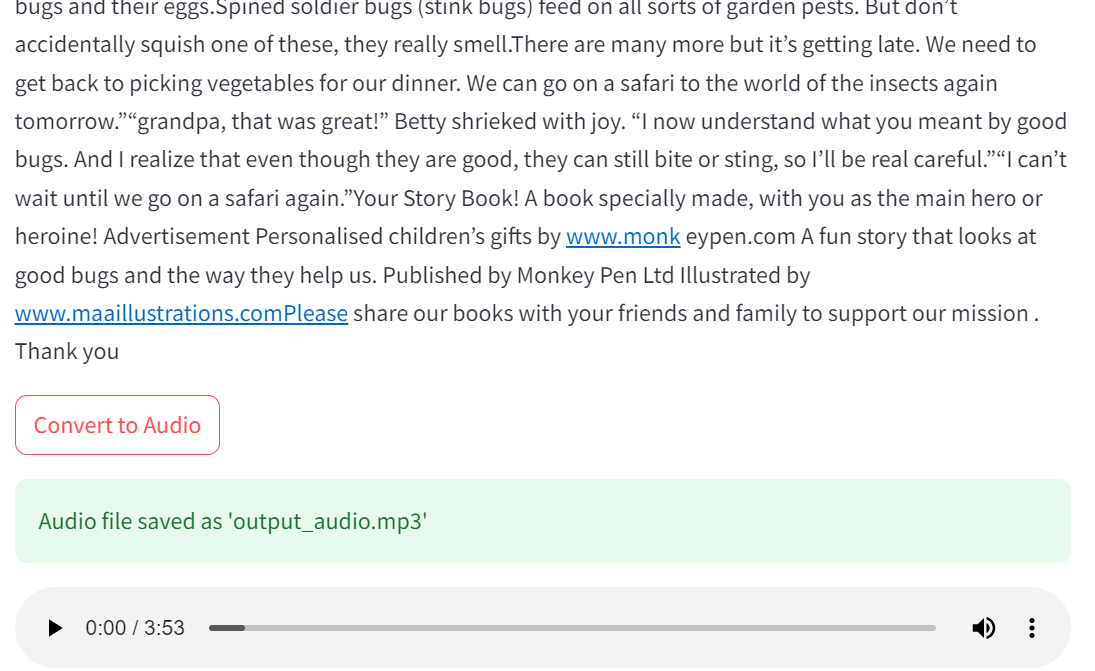
st.success("Audio file saved as 'output_audio.mp3'"): Shows success message.
st.audio('output_audio.mp3'): Adds an audio player for the generated file.
# Streamlit app
st.title("PDF to Audio Converter") # Title of the web app
uploaded_file = st.file_uploader("Choose a PDF file", type="pdf") # File uploader widget
if uploaded_file is not None:
text = extract_text_from_pdf(uploaded_file) # Extract text from the uploaded PDF
# Display extracted text (optional)
st.write("Convert PDF to audiobook:") # Header for extracted text
st.write(text) # Display the extracted text
if st.button("Convert to Audio"): # Button to trigger the conversion
speaker = init_tts_engine() # Initialize the TTS engine
text_to_speech(speaker, text, 'output_audio.mp3') # Convert text to speech and save as MP3
speaker.stop() # Stop the TTS engine
st.success("Audio file saved as 'output_audio.mp3'") # Display success message
st.audio('output_audio.mp3') # Add audio player to play the generated audio file
Running the App
To run the Streamlit app, save the code to a file (e.g., pdf_to_audio.py) and execute the following command:
streamlit run pdf_to_audio.pyOpen the provided URL in your web browser to access the app. Upload a PDF file, extract the text, and convert it to an audio file with a single click.
Complete Code
import PyPDF2
import pyttsx3
import streamlit as st
# Function to initialize the TTS engine with desired properties
def init_tts_engine(rate=190, volume=2.0):
engine = pyttsx3.init() # Initialize the TTS engine
engine.setProperty('rate', rate) # Set the speech rate (words per minute)
engine.setProperty('volume', volume) # Set the volume level (0.0 to 1.0)
# Select the desired voice
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[1].id) # Set the voice to Female
return engine
# Function to read PDF and extract text
def extract_text_from_pdf(pdf_file):
reader = PyPDF2.PdfReader(pdf_file) # Create a PDF reader object
full_text = "" # Initialize an empty string to hold the extracted text
for page_num in range(len(reader.pages)): # Loop through all pages in the PDF
page = reader.pages[page_num] # Get the page object
full_text += page.extract_text() # Extract text from the page and append to full_text
return full_text
# Function to convert text to speech and save to file
def text_to_speech(engine, text, output_file):
engine.save_to_file(text, output_file) # Save the speech to an audio file
engine.runAndWait() # Run the TTS engine to complete the process
# Streamlit app
st.title("PDF to Audio Converter") # Title of the web app
uploaded_file = st.file_uploader("Choose a PDF file", type="pdf") # File uploader widget
if uploaded_file is not None:
text = extract_text_from_pdf(uploaded_file) # Extract text from the uploaded PDF
# Display extracted text (optional)
st.write("Convert PDF to audiobook:") # Header for extracted text
st.write(text) # Display the extracted text
if st.button("Convert to Audio"): # Button to trigger the conversion
speaker = init_tts_engine() # Initialize the TTS engine
text_to_speech(speaker, text, 'output_audio.mp3') # Convert text to speech and save as MP3
speaker.stop() # Stop the TTS engine
st.success("Audio file saved as 'output_audio.mp3'") # Display success message
st.audio('output_audio.mp3') # Add audio player to play the generated audio file
Output

Conclusion
In this blog post, we’ve created a simple yet powerful PDF to audio converter. You can further customize and expand the code to fit your needs. Happy coding!


