

In today’s digital age, extracting text from images has become increasingly useful. Whether you need to digitize printed documents or extract text from images for further processing, Optical Character Recognition (OCR) can be a powerful tool.
In this post, we’ll explore how to use EasyOCR, a robust and easy-to-use Python library, to extract text from images. We’ll also build a simple web application using Streamlit to make the process interactive and user-friendly.
Prerequisite
Make sure you have python installed. Open your terminal and run the following command:
pip install streamlit easyocrThis will install both Streamlit and EasyOCR in your environment.
Step 1: Import necessary libraries
Start by importing the required libraries:.
import streamlit as st
import easyocr
from PIL import Image
import numpy as npStep 2: Building the Streamlit App
Next, let’s create a simple Streamlit app that allows users to upload an image and then extracts and displays the text from the image using EasyOCR. So, let’s write the main function for our app. This function will handle the file upload, image display, and text extraction.
def main():
st.title("Image Text Extraction with EasyOCR")
# Upload image
uploaded_image = st.file_uploader("Upload an image", type=["jpg", "jpeg", "png"])
if uploaded_image is not None:
# Display the uploaded image
image = Image.open(uploaded_image)
st.image(image, caption='Uploaded Image', use_column_width=True)
# Convert the image to a format suitable for EasyOCR
image_np = np.array(image)
# Initialize the EasyOCR reader
reader = easyocr.Reader(['en'], gpu=False) # Set GPU=True if you want to use GPU
# Perform text detection
result = reader.readtext(image_np)
# Display the extracted text
st.subheader("Extracted Text:")
extracted_text = "\n".join([text[1] for text in result])
st.write(extracted_text)
if __name__ == "__main__":
main()While EasyOCR is easy to use, it’s important to understand some key points that might affect the performance and accuracy of the OCR:
- Language Support: EasyOCR supports over 80 languages. You can specify the languages to be used when initializing the
Reader. This is useful if your images contain text in multiple languages. - GPU vs. CPU: By default, EasyOCR runs on the CPU, which might be slow for large or complex images. If you have a compatible GPU, you can enable GPU support by setting
gpu=Truewhen initializing theReader. - Performance Considerations: For large images or documents with a lot of text, consider resizing the images or cropping them to focus on the areas of interest. This can significantly speed up the OCR process.
Step 3: Running the App
Save the file as app.py . In your terminal, navigate to the directory where your app.py file is located and run the following command:
streamlit run app.pyThis will start the Streamlit server, and you’ll see a link in your terminal. Open that link in your web browser to view the app.
Complete Code
import streamlit as st
import easyocr
from PIL import Image
import numpy as np
def main():
st.title("Image Text Extraction with EasyOCR")
# Upload image
uploaded_image = st.file_uploader("Upload an image", type=["jpg", "jpeg", "png"])
if uploaded_image is not None:
# Display the uploaded image
image = Image.open(uploaded_image)
st.image(image, caption='Uploaded Image', use_column_width=True)
# Convert the image to a format suitable for EasyOCR
image_np = np.array(image)
# Initialize the EasyOCR reader
reader = easyocr.Reader(['en'], gpu=True) # Set GPU=True if you want to use GPU
# Perform text detection
result = reader.readtext(image_np)
# Display the extracted text
st.subheader("Extracted Text:")
extracted_text = "\n".join([text[1] for text in result])
st.write(extracted_text)
if __name__ == "__main__":
main()
n__":
main()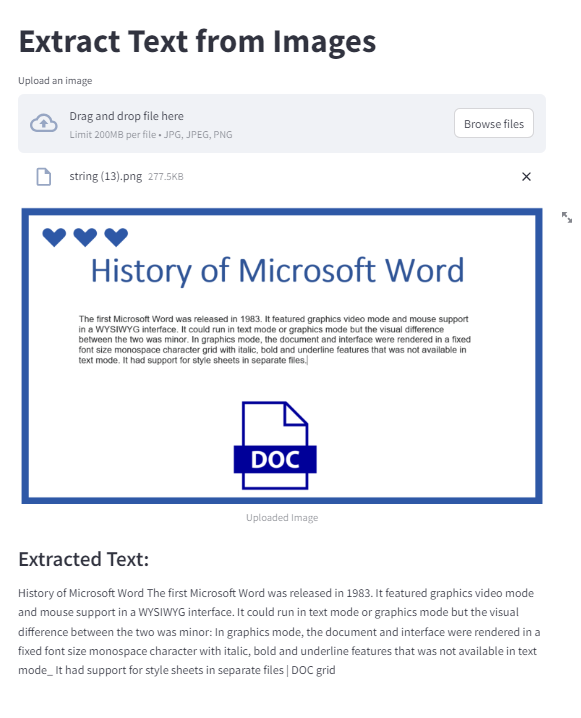
Conclusion
In this post, we’ve built a simple yet powerful web app that can extract text from images using EasyOCR and Streamlit. This tool can be handy for various applications, from digitizing documents to extracting information from images.


